{kind=link}
3D Style Transfer in VR
NeRF, Style Transfer, VR
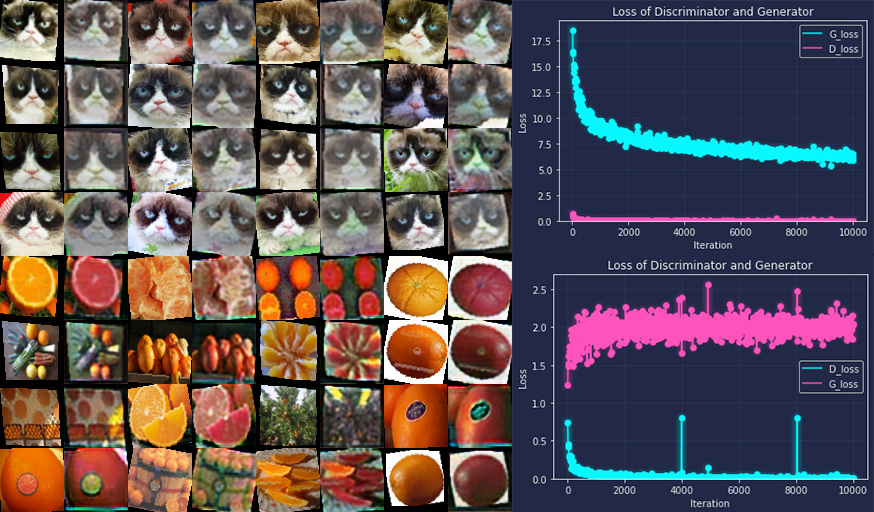
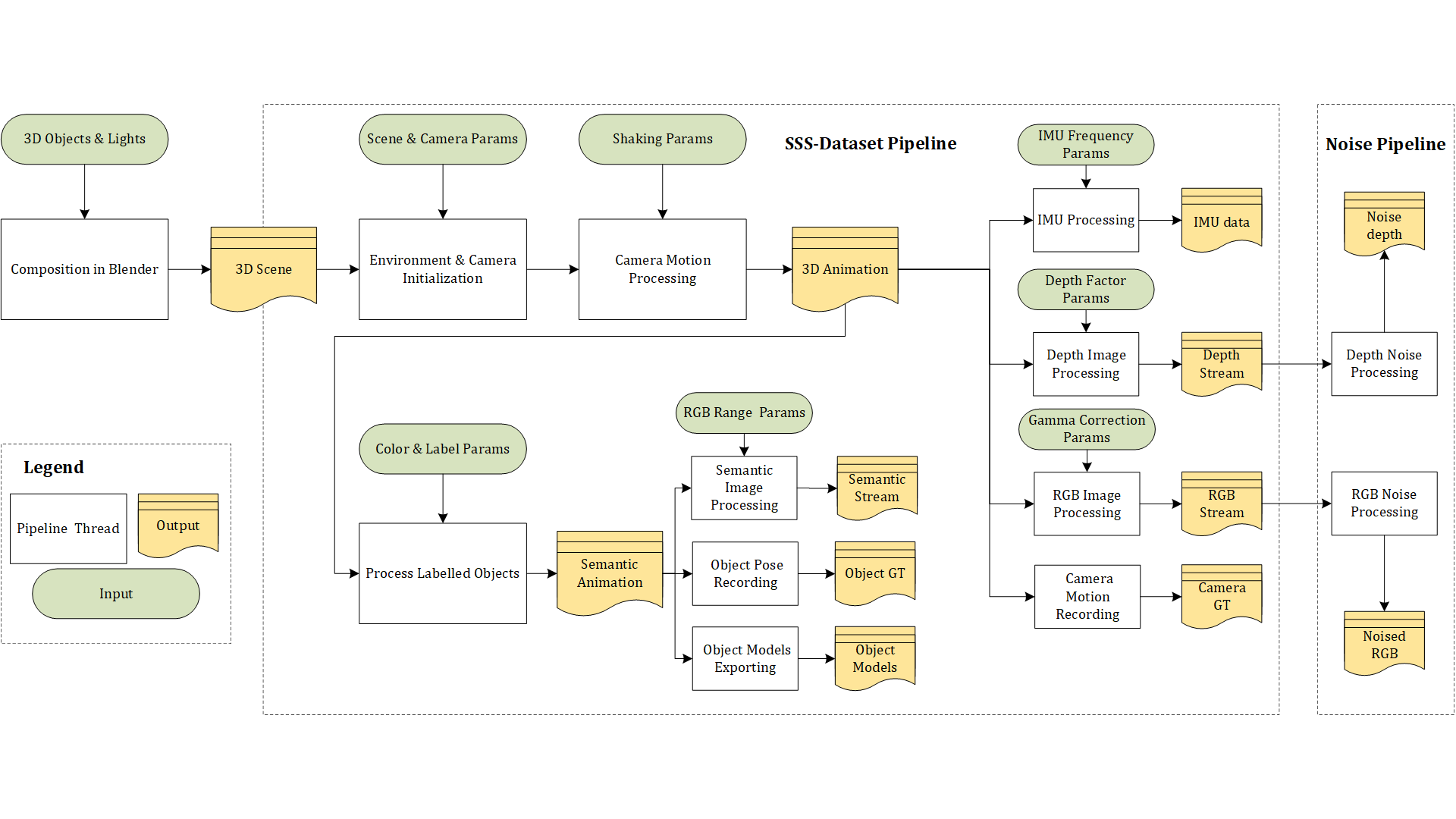
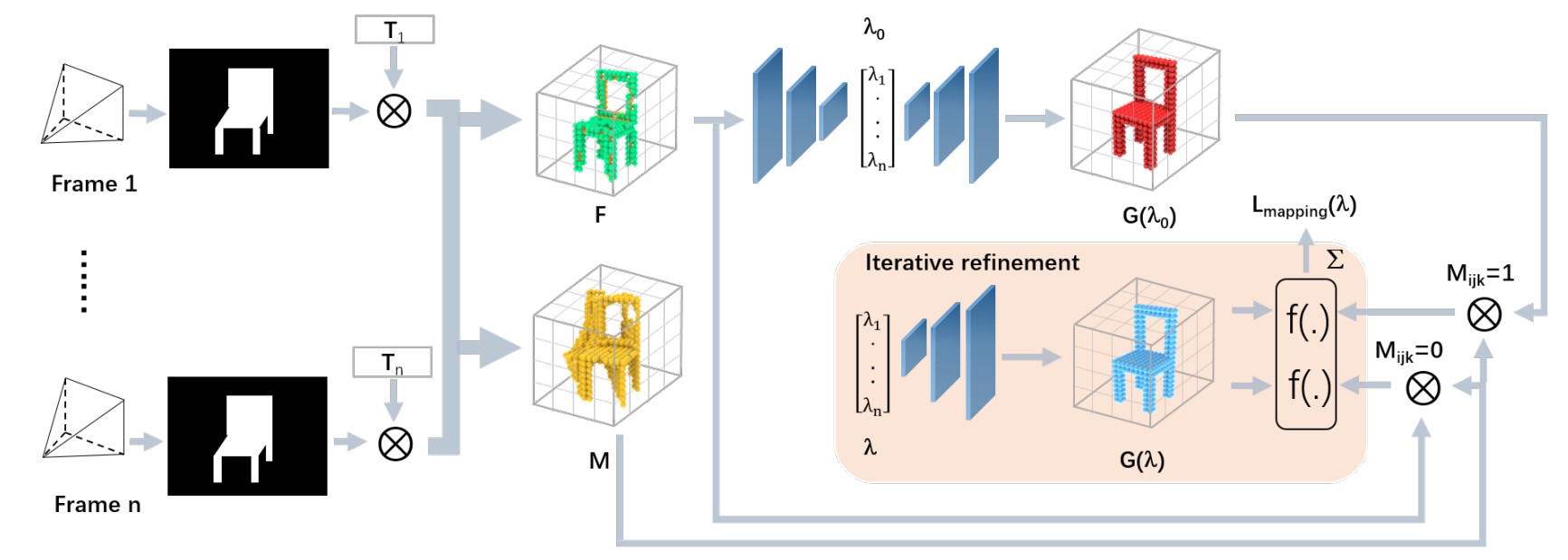
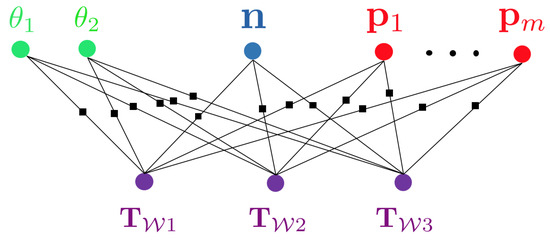
This work takes NeRF as a backbone, exploring and experimenting with different methods to make 3D style transfer possible, by combining 2D style transfer technique with photo-realistic 3D scenes from NeRF. And it then explores the applications that can utilize such techniques to achieve architecture design and art creation in a fashion of 3D-aware style control and transfer. To explore the topic, the generation of the datasets for the network is discussed, and different ways of combining NeRF network and Style transfer network are implemented and analyzed, including latent space embedding of various features and concatenation of two networks. Finally, the 3D style scene is put in the VR for an immersive experience.
[Github]{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}